My name is Lucas Lima, and over the past few months I have been conducting research with Prof. Edil Medeiros in the area of Fountain Codes applied to Bitcoin, as suggested by Olaoluwa Osuntokun. Thanks Vinteum for sponsoring this work through the fellowship program.
Introduction
At the time of writing, the Bitcoin blockchain already exceeds 740 GB of storage. This continuous growth in blockchain size represents a challenge for running full nodes, since maintaining a complete copy of the history requires increasingly more disk space and computational resources, raising the operational cost of those nodes.
As an alternative, many users choose to run pruned nodes, which fully validate blocks and transactions but discard older parts of the blockchain after validation, keeping only the most recent data needed for the node to function. However, pruned nodes can’t contribute to the Initial Block Download (IBD) for bootstrapping nodes.
The proposal of the Fountain Codes-based architecture is to allow pruned nodes to help the network serve historical block data without imposing too much storage overhead on them. This is achieved by dividing the blockchain into fixed-size periods, where each division is called an epoch, and then encoding each of those epochs. The technique is randomized and doesn’t require coordination among peers.
Nodes following this architecture would no longer store the entire blockchain, but rather these encodings, referred to as droplets, along with block headers. When a new node following the architecture joins the network, it can reconstruct blockchain epochs by collecting enough droplets, and also verify the validity of the encoded droplets. There are no additional trust assumptions on top of the existing Bitcoin protocol.
Fountain Codes architecture
The architecture presented is based on the paper [1], which uses Luby Transform Code (LT Code), a family of Fountain Codes. The core idea of this type of code is to transform a set of k original blocks into a potentially large number of encoded blocks, which we call droplets. Each droplet is generated by selecting some original blocks according to a degree distribution and combining those blocks with XOR.
Within this architecture, we can have three kinds of nodes on the network:
Droplet nodes: nodes that have already validated blocks but no longer store the entire original blockchain. Instead, they keep block headers and a set of droplets for each epoch.
Bucket nodes: nodes in the bootstrapping process. They collect droplets from droplet nodes, organize data by epoch, and run the decoding process to reconstruct the original blocks. After recovering and validating the blockchain, a bucket node can act as a droplet node or a full node.
Murky Nodes: malicious nodes that distribute corrupted droplets (murky droplets) to hinder epoch reconstruction. During bootstrap, the bucket node detects these droplets by checking whether there is a match between the header and the Merkle root of each singleton against the header-chain, rejecting the invalid ones.
As a result, reconstruction does not depend on receiving specific droplets. The bucket node only needs to collect a sufficient number of honest droplets for the decoding process to recover the original blocks. LT Codes allow different nodes to store different droplets for the same epoch, and a new node can recover the blockchain by combining data received from multiple sources. Additionally, since epochs are independently encoded, a droplet node can download droplets in parallel and unencoded blocks from full nodes.
Encoding
The encoding process is the step in which a node transforms already-validated blockchain blocks into droplets. The idea is that the node does not encode the entire blockchain at once, but rather in epochs. An epoch is defined as the period needed for the blockchain to grow by k blocks. For example, if k = 1000, then each group of 1000 blocks forms an epoch.
When an epoch ends, the node takes the sub-chain corresponding to those k blocks and generates s droplets from it. Each droplet is an encoded chunk, produced through combinations of some of the original blocks from that epoch. After generating these droplets, the node can discard the original blocks from that epoch and keep only the corresponding droplets, saving space.
Step-by-step of the encoding process:
The node selects an epoch, i.e., a set of
kalready-validated blocks:B1, B2, ..., Bk.To generate a droplet
Cj, the node draws a degreedbetween1andk, following a given probability distribution.Then, the node randomly selects
ddistinct blocks within that epoch. These blocks are called the neighbors of the droplet.The content of the droplet is computed by taking the bitwise XOR of those
dblocks:
where $B_{i_x}$ denotes one of the $d$ source blocks selected during the encoding process.
Along with the droplet, the node stores a way to identify which blocks participated in the combination, i.e., which blocks were used to encode that droplet.
The process is repeated until the node generates
sdroplets for that epoch.After that, the node can delete the
koriginal blocks of that epoch and keep only thesdroplets, the vectors indicating their neighbors, and the header-chain.
One important point is that this doesn’t require pruned nodes to keep the full historical blockchain or introduce any additional security assumption. Pruned nodes already store the full header chain and also a window of recent full blocks to handle possible chain reorganizations. The only additional storage required by this scheme is the encoded droplets.
Decoding
The decoding process occurs when a new node wants to recover the blockchain from the droplets stored by other nodes. This new node is called a bucket node in the paper, because it works like a bucket collecting drops from the fountain. It contacts several droplet nodes and downloads droplets for each blockchain epoch.
For each epoch, the bucket node needs to collect enough droplets to reconstruct the k original blocks of that sub-chain. Because the droplets were created with Fountain Codes, the node does not need to receive specific droplets from specific nodes: in principle, any sufficiently large set of honest droplets can allow reconstruction. This is one of the useful properties of this architecture, because it avoids depending on a specific archival node.
After collecting the droplets, the node runs the decoding algorithm to recover the original blocks of each epoch. This reconstruction also uses the blockchain headers to verify that the recovered blocks match the Merkle roots present in the headers and to identify malicious droplets, called murky droplets in the paper. Thus, decoding does not only serve to reconstruct the data, but also to filter out invalid contributions from adversarial nodes.
Step-by-step of the decoding process:
The bucket node downloads droplets from several droplet nodes for the same epoch. If it contacts
nnodes and each one storessdroplets per epoch, then it will have up ton * sdroplets to attempt reconstructing thekoriginal blocks.Each droplet carries information about which original blocks were combined to produce it. Using this information, the decoder builds a bipartite graph connecting droplets to their source blocks.
The algorithm looks for a droplet connected to only one still-unknown block. This type of droplet is called a
singleton.If no singleton exists, the algorithm cannot advance with the current set of droplets. To continue, the node must download additional droplets for that epoch from other nodes and retake the decoding process.
If a singleton exists, the algorithm treats the content of that droplet as a candidate for the corresponding original block.
Before accepting the block, a verification is performed to check whether it is consistent with the header chain. To do this, the expected header and the Merkle root computed from the block payload are compared with the Merkle root stored in the true header.
If the verification fails, the droplet is considered malicious or invalid, and is removed from the graph.
If the verification passes, the block is accepted as recovered.
Once a block is recovered, the algorithm removes its contribution from the other droplets that depended on that block. This is done by applying XOR again:
new_droplet = current_droplet XOR recovered_block
Next, the edges linked to the recovered block are removed from the graph.
This process repeats: find singletons, verify, accept or reject, remove contributions, and update the graph.
Decoding succeeds when all
kblocks of the epoch have been recovered. If at any point there are no more singletons and unknown blocks still remain, decoding can’t proceed and the node needs to collect more droplets.
When the bucket node finishes the reconstruction, it validates the recovered blocks. After that, it can also encode the blockchain into droplets and immediately start acting as a droplet node for that epoch of the blockchain, contributing to the bootstrapping of other nodes.
The minimum number of honest droplets a bucket node must collect to recover an epoch with probability at least $1 - \delta$ is:
$$ k + O\!\left(\sqrt{k}\,\ln^2\!\left(\frac{k}{\delta}\right)\right) $$Since each droplet node stores $s$ droplets per epoch, each node must contact at least $\frac{1}{s}\left(k + O\!\left(\sqrt{k}\,\ln^2\!\left(\frac{k}{\delta}\right)\right)\right)$ honest nodes to ensure reconstruction.
If you would like to see a step-by-step example of the encoding and decoding processes, check out this gist.
Robust Soliton Distribution
In the encoding step, each droplet needs to choose a degree d, i.e., how many original blocks will be combined to form that droplet. A droplet with degree 1 contains only one original block and is called a singleton. A droplet with high degree contains the XOR of many original blocks and depends on many blocks at the same time.
This choice should not be completely uniform. If many droplets have high degree, the decoder will have difficulty finding singletons to start the decoding process. If many droplets have low degree, they may not carry enough independent information to reconstruct all blocks. The Robust Soliton Distribution is the distribution used to balance these effects.
The intuition is to create droplets with varied degrees, but maintaining enough low-degree droplets to feed the peeling decoder. The decoder depends on singletons to start and continue reconstruction. Every time a block is recovered, its contribution is removed from the other droplets. When enough of a high-degree droplet’s neighbors have already been recovered, that droplet can eventually become a new singleton. Therefore, the degree distribution needs to keep this process alive until all k blocks of the epoch are recovered.
First, the Ideal Soliton Distribution is presented, defined as:
This distribution has an interesting theoretical property: on average, it tends to keep the peeling process going with approximately one singleton available per iteration. The problem is that this is fragile. In practice, if at any point the decoder runs out of singletons, the process stops, even if there are still useful droplets in the graph.
To make this more robust, the Robust Soliton Distribution adds a correction $\theta(d)$ to the ideal distribution. This correction increases the probability of certain degrees, especially lower ones, to reduce the chance of the decoder running out of singletons during reconstruction.
For parameters $0 < \delta < 1$ and c > 0, define:
Then, define the auxiliary function $\theta(d)$:
$$ \theta(d) = \begin{cases} \frac{R}{dk}, & 1 \le d \le \frac{k}{R} - 1, \\\\[1ex] \frac{R}{k}\ln\!\left(\frac{R}{\delta}\right), & d = \frac{k}{R}, \\\\[1ex] 0, & \frac{k}{R} < d \le k. \end{cases} $$The final distribution is obtained by summing the ideal distribution with this correction and normalizing:
$$ \mu(d) = \frac{\rho(d) + \theta(d)}{\beta} $$where:
$$ \beta = \sum_{d=1}^{k} \bigl(\rho(d) + \theta(d)\bigr) $$The graph below illustrates the shape of this distribution.
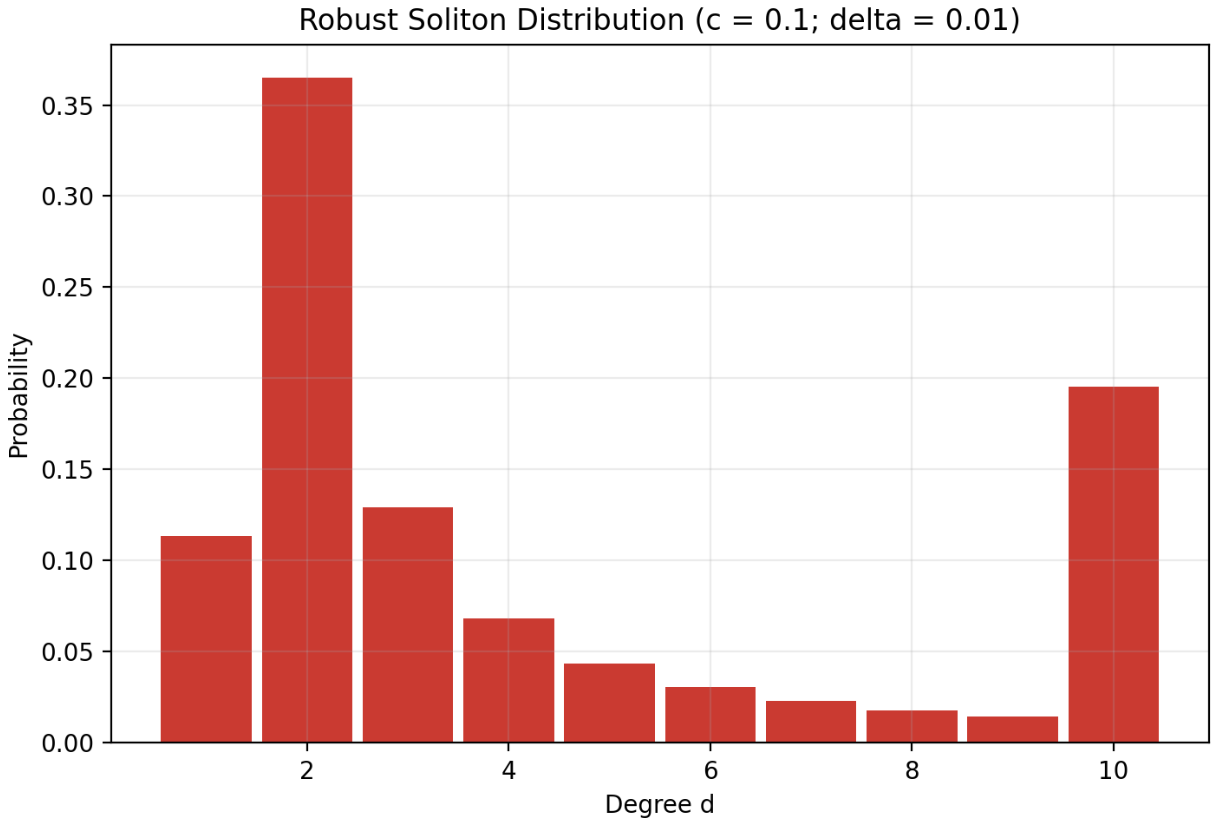
In practice, $\mu(d)$ is the function the encoder uses to draw the droplet degree. That is, when the node is about to generate a new droplet, it draws d according to $\mu(d)$ , picks d random blocks from the epoch, and computes the XOR among them. The parameters play the following roles:
kis the number of blocks in the epoch.dis the degree of a droplet, i.e., how many blocks enter that XOR.Rcontrols the size of the robustness “reserve” added to the ideal distribution.$\delta$ controls an estimate of the probability of decoding failure.
cis a tunable parameter used to calibrate how many extra droplets will be needed in practice, directly proportional to the value ofR. This makes the distribution add more probability mass, especially at low degrees and at the special degree near k / R.
The expected result is that the bucket node needs to collect only slightly more than k honest droplets to reconstruct the k original blocks with high probability. This is the reason the distribution matters: it does not change the basic operation of XOR, but it changes the probability that the graph generated by encoding is easy to decode by the peeling decoder.
Simulations
Producer-Consumer experiment
In this experiment, I simulated a bucket node (consumer) trying to reconstruct an epoch by collecting random droplets. There is another simulated node (producer) that produces droplets for that epoch and sends them to the consumer.
For each configuration of c and $\delta$ in the Robust Soliton Distribution, I repeated the experiment 100 times to see how many droplets are needed for epoch reconstruction.
See references [8] for the the signet blockchain data I used as the epoch for this test.
Results
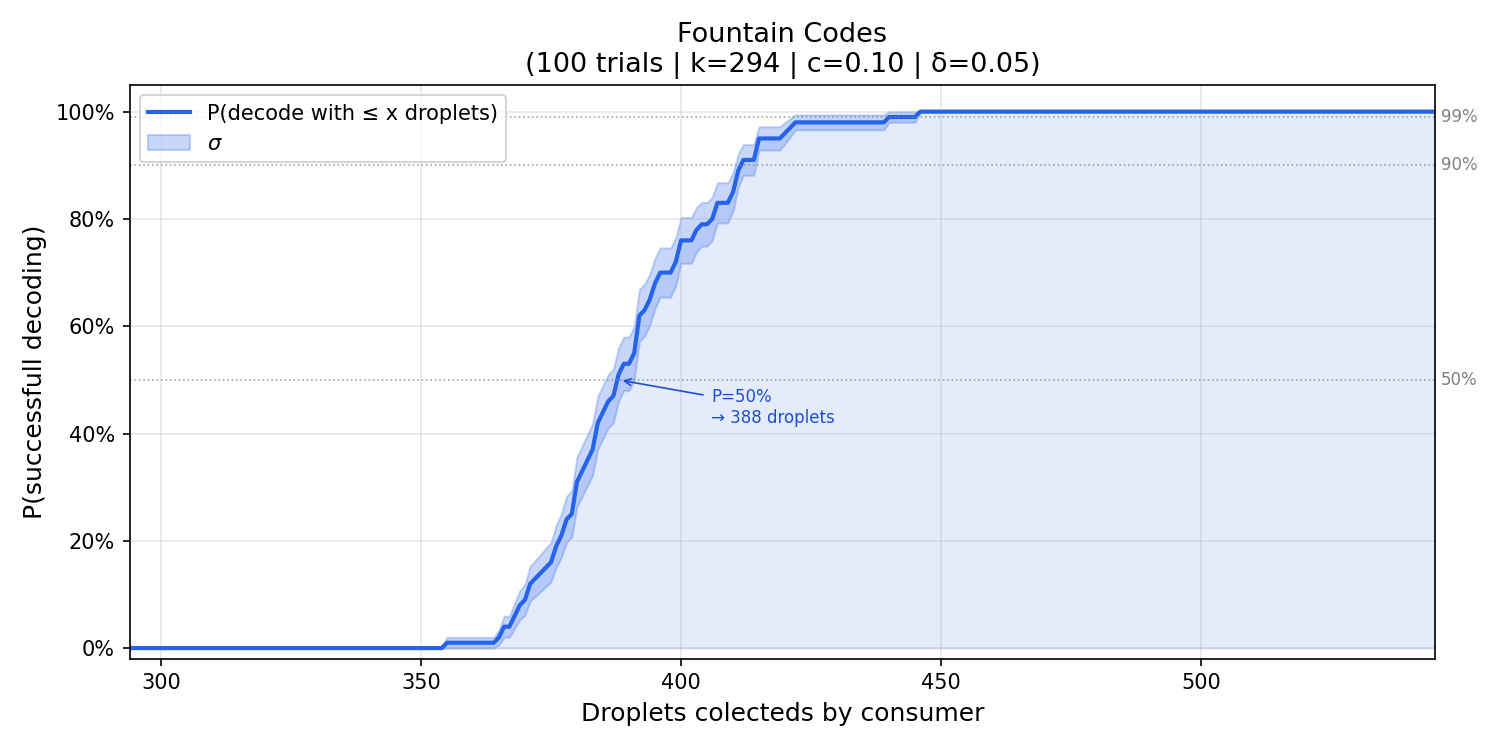
- {c = 0.1, $\delta$ = 0.05}
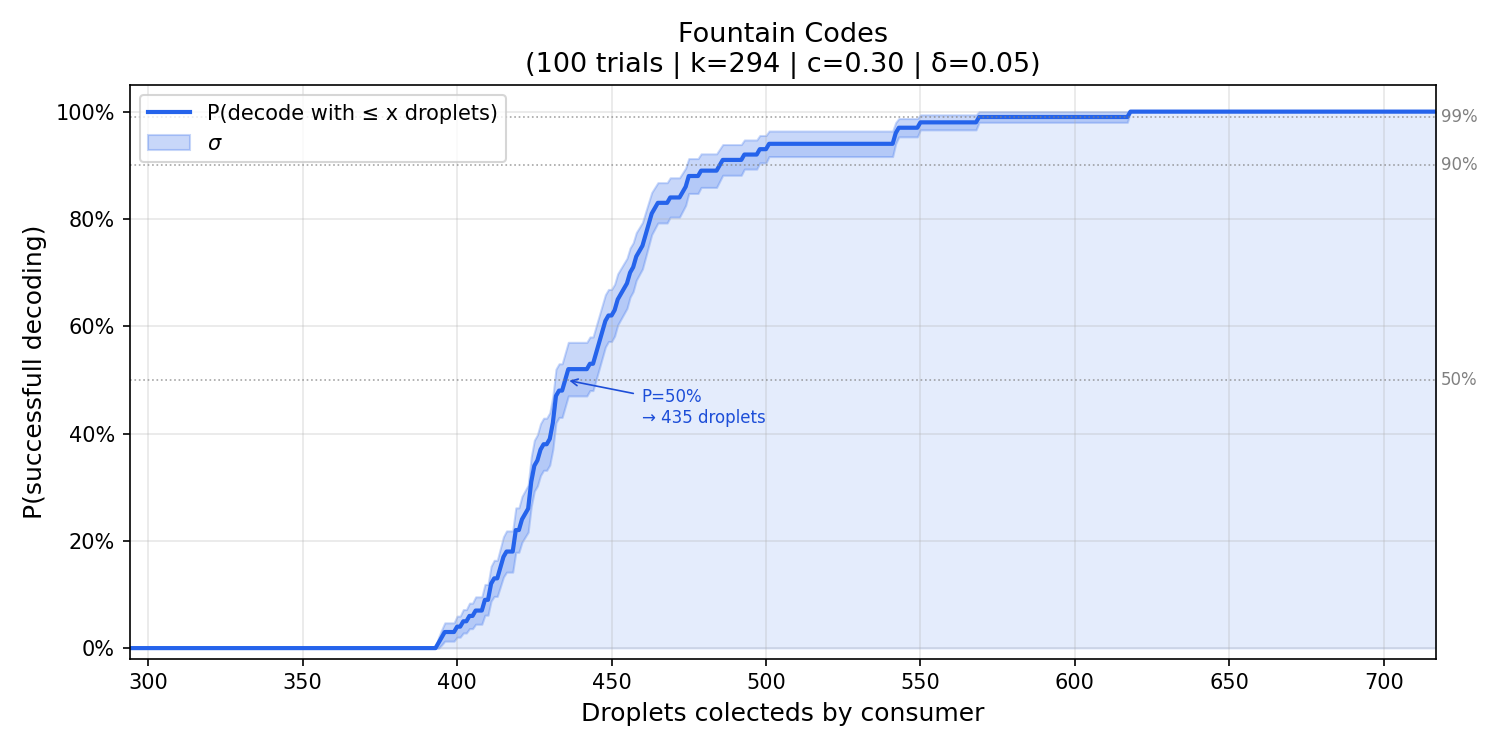
- {c = 0.3, $\delta$ = 0.05}
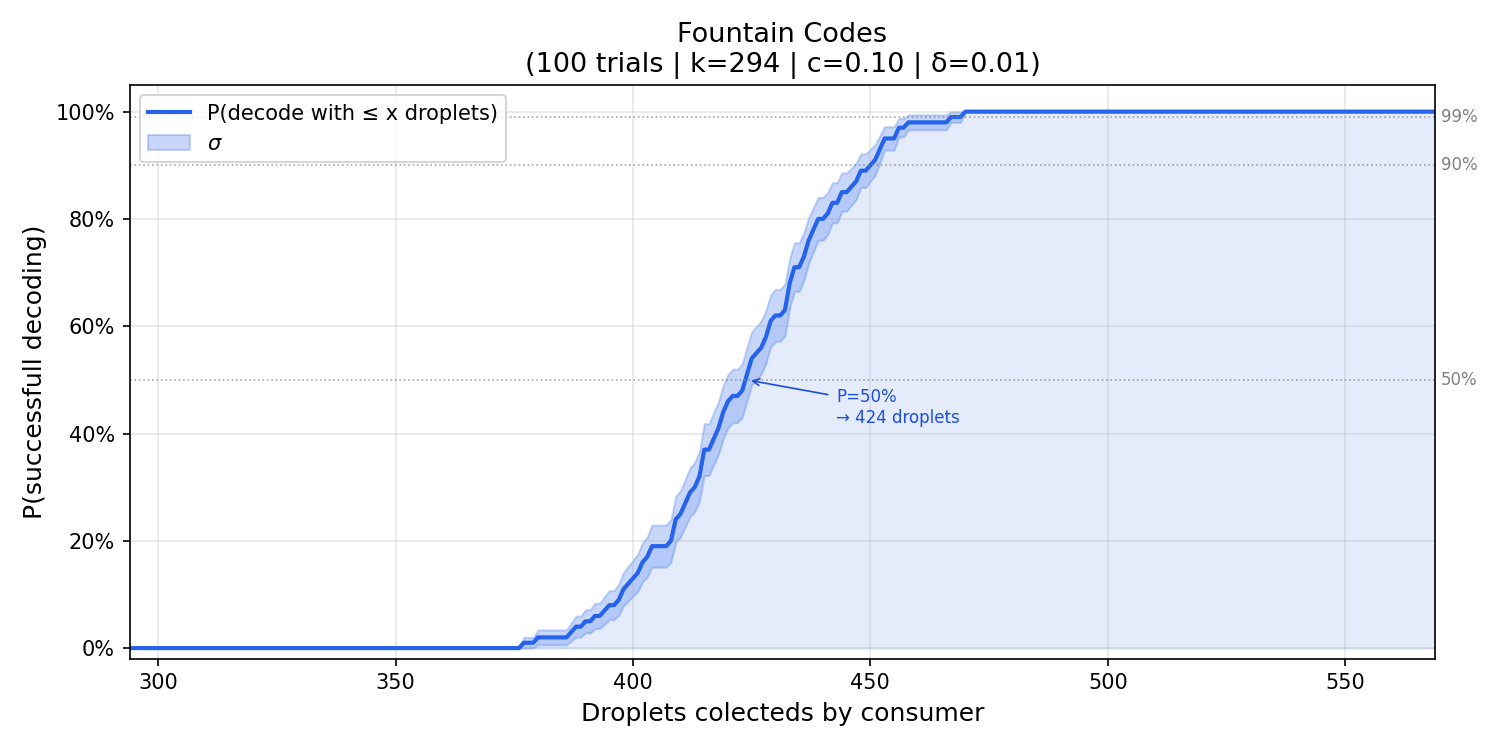
- {c = 0.1, $\delta$ = 0.01}
- {c = 0.3, $\delta$ = 0.01}
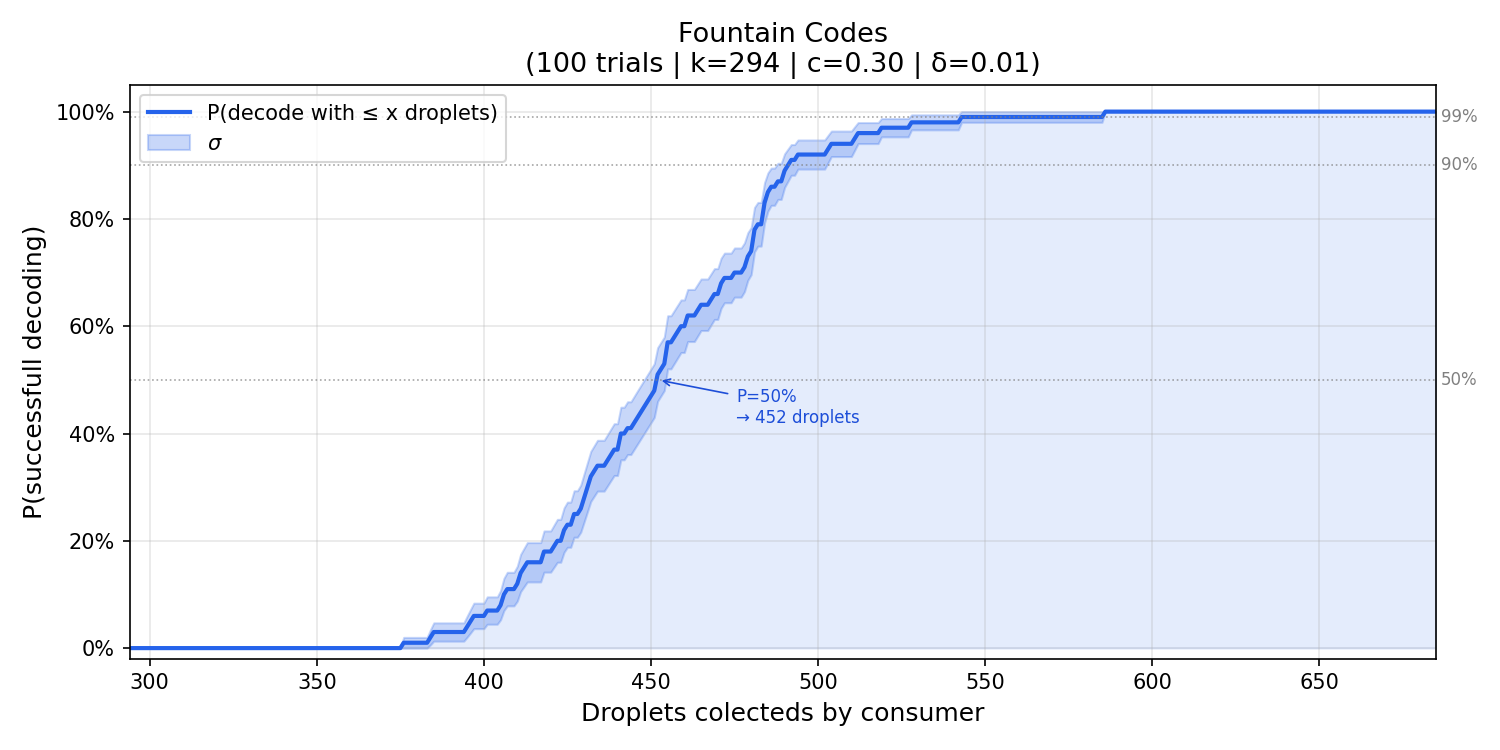
Based on the graphs above, it’s possible to notice:
$\delta$: comparing configurations with the same
cbut different $\delta$ values, reducing $\delta$ from0.05to0.01shifts the histogram slightly to the right, that is, slightly more droplets are needed on average. This is expected, since a smaller $\delta$ makes the distribution more conservative, adding more probability mass at lower degrees to reduce the chance of the decoder stalling.c: comparing configurations with the same $\delta$ but differentcvalues, increasingcfrom0.1to0.3produces a more concentrated histogram. The variance decreases, meaning the number of droplets required becomes more predictable across runs. This happens because a largercincreasesR, which strengthens the robustness correction, keeping the peeling decoder fed with singletons more consistently.
The configuration {c = 0.1, $\delta$ = 0.05} achieves a good balance, the overhead above k stays low and the variance is small, making reconstruction both efficient and predictable.
Open problems
Define values of k, s, c, and $\delta$
An important decision for the PoC is to choose initial values for k, s, c, and $\delta$ .
A larger k (epoch size) tends to improve the efficiency of Fountain Codes, bringing the bootstrap cost closer to the optimal lower bound. On the other hand, a larger k also requires the node to buffer more data before closing the epoch and generating the encoding. For Bitcoin, k = 1000 represents approximately one week of blocks, considering one block every ten minutes.
The value of s, the number of droplets stored per epoch by each node, can be left as a configurable parameter. A smaller s gives the node greater storage savings, while a larger s makes the node contribute more data to the bootstrap process of other nodes. Users with less available storage can store fewer droplets per epoch, while users who want to contribute more to the network can choose a larger value.
So, if we choose k = 1000 and s = 10, the target is approximately 100x storage savings.
The parameters c and $\delta$ enter the Robust Soliton Distribution.
$\delta$ represents an estimate of the tolerated failure probability in decoding: smaller values require more robustness and tend to increase the number of droplets needed.
c controls the extra robustness term of the distribution: larger values help keep singletons available during the peeling decoder, but may also increase overhead.
For an initial PoC, I would use the configuration:
`k = 1000`, `s = 10`, `c = 0.1`, `delta = 0.05`
accepting a smaller savings of approximately 100x.
Evaluate alternative degree distributions
Another open question is whether the Robust Soliton Distribution is the best choice for this architecture, or whether other probability distributions could produce more favorable numbers in practice. The distribution directly affects how many droplets need to be collected, how often the peeling decoder gets stuck, and how much overhead is needed beyond the original k blocks.
Define protocol changes to support Fountain Codes
For this architecture to work in a real implementation, it would also be necessary to define how nodes announce support for Fountain Codes, how they discover available droplets, and how they exchange that data over the network, while maintaining compatibility with other nodes. Among the main protocol topics to be defined in the spec, I see:
Support signaling: the node needs to announce that it understands Fountain Codes, possibly through a new service flag in the handshake, such as
NODE_FOUNTAIN. This way, compatible peers could activate specific messages for droplets. Another way to signal this capability would be through BIP-434.Peer messages: the protocol needs to define messages for discovering, requesting, and sending droplets between peers. A bucket node must be able to query which epochs a peer has, discover which droplets are available, and request specific droplets or a number of droplets for an epoch.
These messages could follow a logic similar to
inv/getdata, but oriented toward Fountain Codes, carrying fields such asepoch_id, droplet degree, and encoded payload. Ideally, the protocol would use deterministic seeds to derive the neighbors, avoiding the transmission of large vectors.Bootstrap flow: the general flow would be connect to peers, identify which ones support Fountain Codes, query available epochs, collect droplets from multiple peers, run decoding, verify the reconstructed blocks against the header-chain, and request more droplets if decoding fails.
Even with
deltabeing set to values that make the probability of successful decoding high, it is not possible to make this value 100% with Fountain Codes alone. For cases where decoding fails even after collecting droplets from all fountain nodes, having a fallback to request the blocks that were not reconstructed in the epoch could be a good option.Handling invalid droplets and the nodes that sent them: the protocol also needs to define how to handle murky droplets. When a droplet produces an invalid candidate block, the node should discard that data and record the peer’s behavior, potentially limiting new requests, disconnecting, or penalizing peers that repeatedly send invalid data.
Next steps
As next steps, I am working on an initial PoC integrating Fountain Codes into btcd. The choice of btcd is interesting not only because it is a Go implementation, which aligns well with the current PoC, but also because it has been used as an experimentation platform for Utreexo, another less orthodox proposal that touches validation, storage assumptions, and P2P behavior. This makes btcd a good environment to test Fountain Codes before thinking about a more formal protocol proposal.
The first goal of this integration is to validate the basic flow within a real node: tracking new blocks, grouping blocks into epochs, generating droplets, persisting the necessary metadata, and allowing another node to reconstruct an epoch from the collected droplets.
After that, the next step is to create a test environment with multiple nodes to measure the behavior of the proposal under conditions closer to a real network.
With those results, the next step would be to mature a protocol specification and then think about the possible writing of a BIP.
References
Swanand Kadhe, Jichan Chung, and Kannan Ramchandran. 2019. SeF: A Secure Fountain Architecture for Slashing Storage Costs in Blockchains. https://arxiv.org/pdf/1906.12140
Gauri Joshi, Joong Bum Rhim, John Sun and Da Wang. 2010. Fountain Codes. https://www.andrew.cmu.edu/user/gaurij/FountainCodes.pdf.
Changlin Yang, Kwan-Wu Chin, Jiguang Wang, Xiaodong Wang, Ying Liu, and Zibin Zheng. 2024. Scaling Blockchains with Error Correction Codes: A Survey on Coded Blockchains. ACM Comput. Surv. 56, 6, Article 139 (January 2024), 33 pages. https://doi.org/10.1145/3637224
Japneet Singh, Adrish Banerjee and Hamid Sadjadpour. 2022. Secure and Private Fountain Code based Architecture for Blockchains.
Qin Huang, Li Quan, and Shengli Zhang. 2022. Downsampling and Transparent Coding for Blockchain.
Aayush Tiwari, V. Lalitha. 2021. Secure Raptor Encoder and Decoder for Low Storage Blockchain.
Rudrashish Pal. 2020. Fountain Coding for Bootstrapping of the Blockchain.
Sample signet used on Producer-Consumer test: https://github.com/vinteum-bdl/infra-signet-server/tree/main/datadir_miner/signet
Fork of the Secure Fountain implementation (Fountain Codes using LT Codes): https://github.com/lucasdbr05/sef
Roasbeef’s (Olaoluwa Osuntokun) thread on X about Fountain Codes: https://x.com/roasbeef/status/1973914845247594840
Fountain Code process step-by-step in a toy example: https://gist.github.com/lucasdbr05/d4dab24f57f7a00491252c69416661bf